Documentation Index
Fetch the complete documentation index at: https://dripart-mintlify-e28287af.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
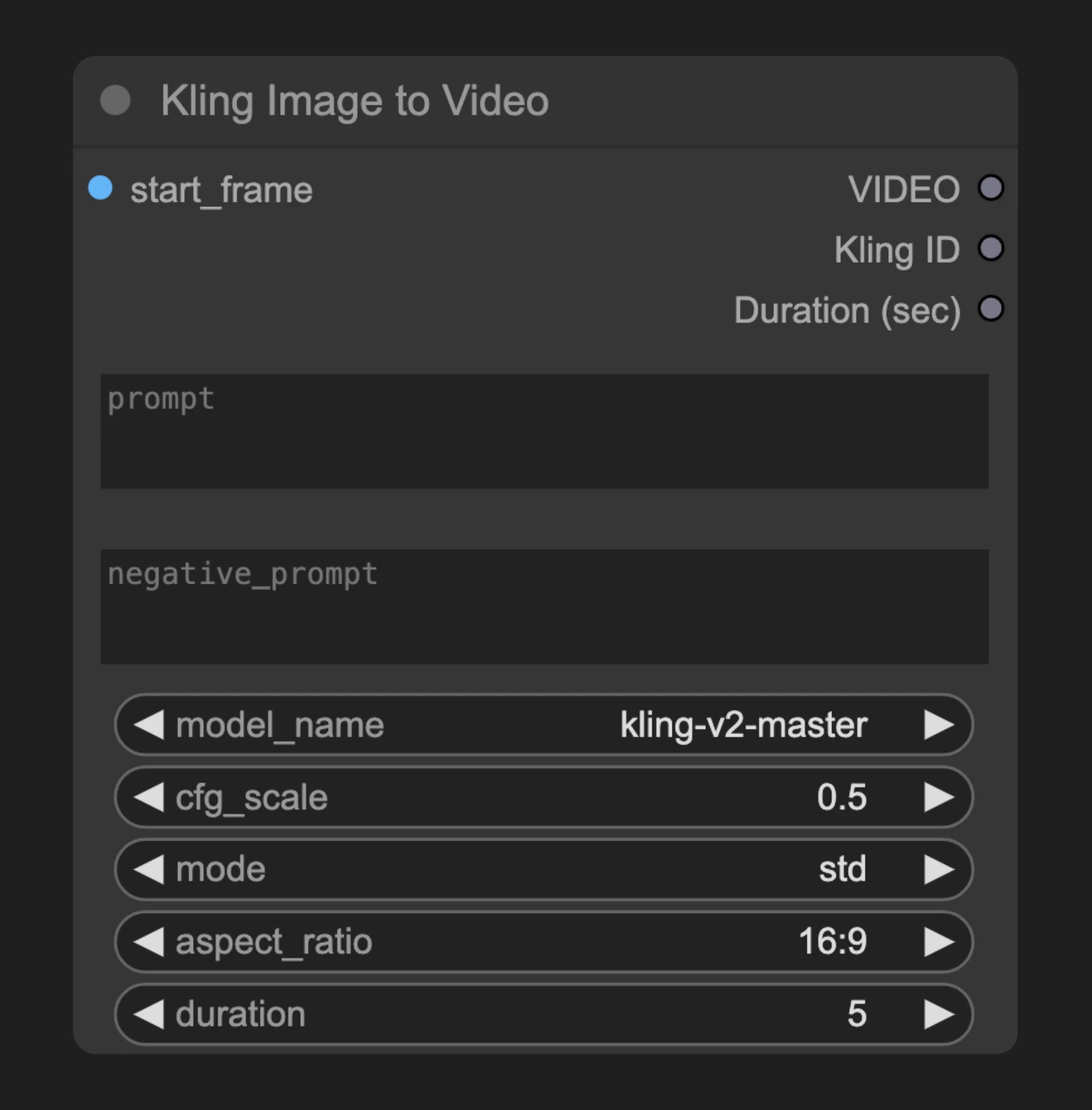
パラメーター
基本パラメーター
以下のすべてのパラメーターは必須です:| パラメーター | 型 | デフォルト値 | 説明 |
|---|---|---|---|
| start_frame | 画像 | - | 入力元の静止画像 |
| prompt | 文字列 | "" | 動画の動作および内容を記述するテキストプロンプト |
| negative_prompt | 文字列 | "" | 動画に含めたくない要素 |
| cfg_scale | 浮動小数点数 | 7.0 | プロンプトへの従い具合を制御するパラメーター |
| model_name | 選択 | ”kling-v1-5” | 使用するモデルの種類 |
| aspect_ratio | 選択 | ”16:9” | 出力動画のアスペクト比 |
| duration | 選択 | ”5s” | 生成される動画の再生時間 |
| mode | 選択 | ”pro” | 動画生成モード |
出力
| 出力 | 型 | 説明 |
|---|---|---|
| VIDEO | 動画 | 生成された動画 |
| video_id | 文字列 | 動画の固有識別子 |
| duration | 文字列 | 動画の実際の再生時間 |
ソースコード
[ノードのソースコード(2025-05-03 更新)]
class KlingImage2VideoNode(KlingNodeBase):
"""Kling Image to Video Node"""
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"start_frame": model_field_to_node_input(
IO.IMAGE, KlingImage2VideoRequest, "image"
),
"prompt": model_field_to_node_input(
IO.STRING, KlingImage2VideoRequest, "prompt", multiline=True
),
"negative_prompt": model_field_to_node_input(
IO.STRING,
KlingImage2VideoRequest,
"negative_prompt",
multiline=True,
),
"model_name": model_field_to_node_input(
IO.COMBO,
KlingImage2VideoRequest,
"model_name",
enum_type=KlingVideoGenModelName,
),
"cfg_scale": model_field_to_node_input(
IO.FLOAT, KlingImage2VideoRequest, "cfg_scale"
),
"mode": model_field_to_node_input(
IO.COMBO,
KlingImage2VideoRequest,
"mode",
enum_type=KlingVideoGenMode,
),
"aspect_ratio": model_field_to_node_input(
IO.COMBO,
KlingImage2VideoRequest,
"aspect_ratio",
enum_type=KlingVideoGenAspectRatio,
),
"duration": model_field_to_node_input(
IO.COMBO,
KlingImage2VideoRequest,
"duration",
enum_type=KlingVideoGenDuration,
),
},
"hidden": {"auth_token": "AUTH_TOKEN_COMFY_ORG"},
}
RETURN_TYPES = ("VIDEO", "STRING", "STRING")
RETURN_NAMES = ("VIDEO", "video_id", "duration")
DESCRIPTION = "Kling Image to Video Node"
def get_response(self, task_id: str, auth_token: str) -> KlingImage2VideoResponse:
return poll_until_finished(
auth_token,
ApiEndpoint(
path=f"{PATH_IMAGE_TO_VIDEO}/{task_id}",
method=HttpMethod.GET,
request_model=KlingImage2VideoRequest,
response_model=KlingImage2VideoResponse,
),
)
def api_call(
self,
start_frame: torch.Tensor,
prompt: str,
negative_prompt: str,
model_name: str,
cfg_scale: float,
mode: str,
aspect_ratio: str,
duration: str,
camera_control: Optional[KlingCameraControl] = None,
end_frame: Optional[torch.Tensor] = None,
auth_token: Optional[str] = None,
) -> tuple[VideoFromFile]:
validate_prompts(prompt, negative_prompt, MAX_PROMPT_LENGTH_I2V)
initial_operation = SynchronousOperation(
endpoint=ApiEndpoint(
path=PATH_IMAGE_TO_VIDEO,
method=HttpMethod.POST,
request_model=KlingImage2VideoRequest,
response_model=KlingImage2VideoResponse,
),
request=KlingImage2VideoRequest(
model_name=KlingVideoGenModelName(model_name),
image=tensor_to_base64_string(start_frame),
image_tail=(
tensor_to_base64_string(end_frame)
if end_frame is not None
else None
),
prompt=prompt,
negative_prompt=negative_prompt if negative_prompt else None,
cfg_scale=cfg_scale,
mode=KlingVideoGenMode(mode),
aspect_ratio=KlingVideoGenAspectRatio(aspect_ratio),
duration=KlingVideoGenDuration(duration),
camera_control=camera_control,
),
auth_token=auth_token,
)
task_creation_response = initial_operation.execute()
validate_task_creation_response(task_creation_response)
task_id = task_creation_response.data.task_id
final_response = self.get_response(task_id, auth_token)
validate_video_result_response(final_response)
video = get_video_from_response(final_response)
return video_result_to_node_output(video)